お手軽だということで Redis をストレージエンジンとした Zipkin サーバーを使っていましたが、Redis ではメモリに収める必要があり、データ容量的に足りなくなったため Cassandra を使うことにしました。 ここでは CentOS 6.6 へ Cassandra と Zipkin サーバーをセットアップする手順を記しておきます。Zipkin をアプリに組み込む方法には触れません。 Zipkin とは Twitter が開発している分散トレーシングツールで、今ちょっとバズってるマイクロサービスを進めていくとどのサービスのどこが遅いのかを知る必要がでてきて、リクエスト毎にアプリをまたいだトレースができるツールです。「LINEのマイクロサービス環境における分散トレーシング « LINE Engineers’ Blog」を読むとわかりやすいかもしれません。(お金があって対応言語などがマッチしていれば AppDynamics が良いと思いますけどね)
構成はサーバー4台それぞれに Zipkin と Cassandra をインストール。Zipkin Collector へのアクセスを HAProxy で4台に振り分ける。keepalived でうち1台に VIP をもたせる。(Ansible の Playbook 貼れば終わりなんだけど…)
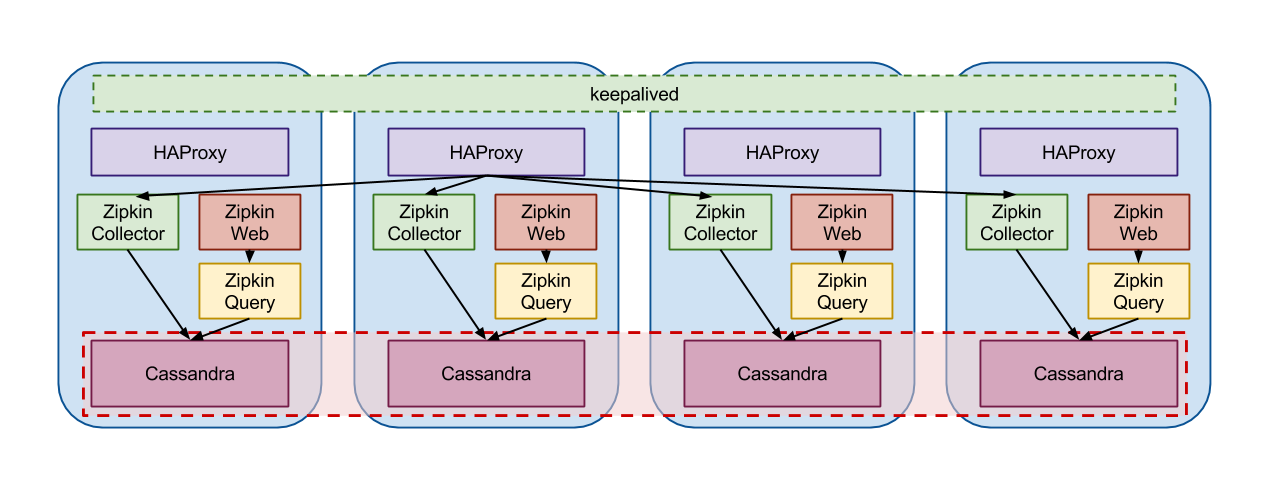
Zipkin+Cassandra
Redis の時に Zipkin Collector が過負荷でどうしようもなかったので、Zipkin サーバーも複数並べたくて、どうせならということで Cassandra サーバーに相乗りさせてみましたが、Cassandra Cluster とは別にしても問題ありません。特に既に Cassandra Cluster が存在する場合など。また、Zipkin Query や Zipkin Web はブラウザからアクセスするサーバーなので沢山並べる必要もありません。今回はどれが故障しても慌てなくて済むように同じ構成のサーバーを並べています。
Cassandra のセットアップ
Cassandra のインストールは DataStax のパッケージを用います。このパッケージには /etc/security/limits.d/cassandra.conf も含まれていて limit まわりも適切に設定してくれます。こういうの重要です。
[datastax]
name = DataStax Repo for Apache Cassandra
baseurl = http://rpm.datastax.com/community
enabled = 0
gpgcheck = 0
$ sudo yum install --enablelrepo=datastax dsc20 cassandra20
vm.max_map_count を変更した方が良いようです。
$ echo 'vm.max_map_count = 131072' | sudo tee -a /etc/sysctl.conf
$ sudo sysctl -p
Java の Heap Size は /etc/cassandra/default.conf/cassandra-env.sh で設定します。
MAX_HEAP_SIZE と HEAP_NEWSIZE ですが、未設定の場合は搭載メモリから自動で計算されます。
/etc/cassandra/default.conf/cassandra.yaml で Cluster Name と seed サーバーを設定します。4台のうち2台を seed としています。
cluster_name: 'Zipkin Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.1.101,192.168.1.103"
listen_address: 192.168.1.x
rpc_address: 0.0.0.0
これで4台で sudo service cassandra start すれば cluster が構成されます。
Zipkin 用スキーマの作成
https://github.com/twitter/zipkin/blob/master/zipkin-cassandra/src/schema/cassandra-schema.txt にスキーマの定義ファイルがあるのでダウンロードし、
$ cassandra-cli -h localhost -f cassandra-schema.txt
とすることで作成できます。
が、cassandra-cli は deprecated とありますので cqlsh で作ったほうが良いのかも。 cqlsh で DESCRIBE KEYSPACE "Zipkin"; と打てば定義が確認できます。
cassandra-schema.txt を流し込んだだけだと Replication Factor が 1 で4サーバーあっても1台停止すると使えなくなってしまうので 2 に変更します。ついでに class も SimpleStrategy にしてしまいます。複数 DC じゃないので SimpleStrategy。
cqlsh> ALTER KEYSPACE "Zipkin" WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 2 };
ALTER KEYSPACE したら nodetool repair コマンドを実行する必要があります。
cassandra-cli ではなく cqlsh を使ってスキーマを作成する場合は DESCRIBE KEYSPACE で表示される文を使えばできそうな感じです。
cqlsh> DESCRIBE KEYSPACE "Zipkin";
CREATE KEYSPACE "Zipkin" WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': '2'
};
USE "Zipkin";
CREATE TABLE "AnnotationsIndex" (
key blob,
column1 bigint,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "Dependencies" (
key blob,
column1 bigint,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "DurationIndex" (
key blob,
column1 bigint,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "ServiceNameIndex" (
key blob,
column1 bigint,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "ServiceNames" (
key blob,
column1 blob,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'min_sstable_size': '52428800', 'class': 'SizeTieredCompactionStrategy'} AND
compression={'chunk_length_kb': '64', 'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "ServiceSpanNameIndex" (
key blob,
column1 bigint,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='NONE' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'min_sstable_size': '52428800', 'class': 'SizeTieredCompactionStrategy'} AND
compression={'chunk_length_kb': '64', 'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "SpanNames" (
key blob,
column1 blob,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='NONE' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'min_sstable_size': '52428800', 'class': 'SizeTieredCompactionStrategy'} AND
compression={'chunk_length_kb': '64', 'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "TopAnnotations" (
key blob,
column1 bigint,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'sstable_compression': 'LZ4Compressor'};
CREATE TABLE "Traces" (
key blob,
column1 blob,
value blob,
PRIMARY KEY ((key), column1)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='NONE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'sstable_compression': 'LZ4Compressor'};
cqlsh>
古いデータの掃除
放っておくとデータは溜まりっぱなしですが、Zipkin + Cassandra ではデフォルトで7日で TTL が設定されているので Cassandra の compaction を実行することで TTL を過ぎたデータを削除することができます。
nodetool compast を定期的に実行しましょう。
OpsCenter
OpsCenter (http://www.datastax.com/what-we-offer/products-services/datastax-opscenter) を使うとかっちょいい画面でクラスターのモニタリングができます。
$ sudo yum install --enablerepo=datastax opscenter
今回はここのセットアップ方法は省略
Zipkin のセットアップ
/opt/zipkin に collector, query, web をインストールします。 collector, query, web をそれぞれダウンロードします。
https://github.com/twitter/zipkin/releases/
- https://github.com/twitter/zipkin/archive/1.1.0.zip
- https://github.com/twitter/zipkin/releases/download/1.1.0/zipkin-collector-service.zip
- https://github.com/twitter/zipkin/releases/download/1.1.0/zipkin-query-service.zip
- https://github.com/twitter/zipkin/releases/download/1.1.0/zipkin-web.zip
zipkin-collector-seervice.zip, zipkin-query-service.zip, zipkin-web.zip はそのまま /opt/zipkin に展開します。
/opt/zipkin/zipkin-collector-service-1.1.0 /opt/zipkin/zipkin-query-service-1.1.0 /opt/zipkin/zipkin-web-1.1.0 1.1.0.zip は中の zipkin-web というディレクトリだけを取り出して /opt/zipkin/zipkin-web に置きます。
Zipkin の各サービスは Supervisord を使って管理します。
EPEL リポジトリにあります
$ sudo yum install supervisor --enablerepo=epel
Zipkin 用ユーザーを作成します
$ sudo groupadd zipkin
$ sudo useradd -g zipkin zipkin
/etc/supervisord.conf を書いて sudo service supervisord start で 8080/tcp で zipkin-web にアクセスできるはずです。 Zipkin へのデータ登録は 9410/tcp です。
[program:zipkin-collector]
command = /usr/bin/java -Xmn1000m -Xms2000m -Xmx2000m -cp /opt/zipkin/zipkin-collector-service-1.1.0/libs -jar /opt/zipkin/zipkin-collector-service-1.1.0/zipkin-collector-service-1.1.0.jar -f /opt/zipkin/zipkin-collector-service-1.1.0/config/collector-cassandra.scala
user = zipkin
autostart = true
stopwaitsecs = 10
log_stdout = true
log_stderr = true
logfile = /var/log/supervisor/zipkin-collector.log
logfile_maxbytes = 10MB
logfile_backups = 10
[program:zipkin-query]
command = /usr/bin/java -cp /opt/zipkin/zipkin-query-service-1.1.0/libs -jar /opt/zipkin/zipkin-query-service-1.1.0/zipkin-query-service-1.1.0.jar -f /opt/zipkin/zipkin-query-service-1.1.0/config/query-cassandra.scala
user = zipkin
autostart = true
stopwaitsecs = 10
log_stdout = true
log_stderr = true
logfile = /var/log/supervisor/zipkin-query.log
logfile_maxbytes = 10MB
logfile_backups = 10
[program:zipkin-web]
command = /usr/bin/java -cp /opt/zipkin/zipkin-web-1.1.0/libs -jar /opt/zipkin/zipkin-web-1.1.0/zipkin-web-1.1.0.jar -f /opt/zipkin/zipkin-web-1.1.0/config/web-dev.scala -D local_docroot=/opt/zipkin/zipkin-web/src/main/resources
user = zipkin
autostart = true
stopwaitsecs = 10
log_stdout = true
log_stderr = true
logfile = /var/log/supervisor/zipkin-web.log
logfile_maxbytes = 10MB
logfile_backups = 10
[supervisord]
http_port = /tmp/supervisor.sock
pidfile = /var/run/supervisord.pid
minfds = 1024
minprocs = 200
nodaemon = false
loglevel = info
logfile = /var/log/supervisor/supervisord.log
logfile_maxbytes = 10MB
logfile_backups = 10
[supervisorctl]
serverurl = unix:///tmp/supervisor.sock
接続先の Cassandra については /opt/zipkin/zipkin-collector-service-1.1.0/config/collector-cassandra.scala, /opt/zipkin/zipkin-query-service-1.1.0/config/query-cassandra.scala の中で指定します。デフォルトで localhost になっています。
もしもストレージに Redis を使いたい場合は config ディレクトリにある collector-redis.scala, query-redis.scala を使います。
HBase 用のファイルもあります。
Redis ではアクセス(登録)が多いと collector プロセスが全然処理しきれなかったのであまり使われていないのかもしれません。Cassandra に変更したらサクサクになりました。
これで動作はするのですが、デフォルトのままでは collector が DEBUG ログを出力してログの量が多すぎるので次のように書き換えました。
私 Scala はまったくわからないので https://groups.google.com/forum/#!topic/zipkin-user/NwZFPzYeo9I を参考に同僚にやってもらったわけですが。
--- collector-cassandra.scala.orig 2013-08-27 14:55:06.000000000 +0900
+++ collector-cassandra.scala 2015-03-11 09:51:28.629353999 +0900
@@ -13,10 +13,12 @@
* See the License for the specific language governing permissions and
* limitations under the License.
*/
+import com.twitter.zipkin.builder.{ZipkinServerBuilder, Scribe}
import com.twitter.zipkin.builder.Scribe
import com.twitter.zipkin.cassandra
import com.twitter.zipkin.collector.builder.CollectorServiceBuilder
import com.twitter.zipkin.storage.Store
+import com.twitter.logging._
val keyspaceBuilder = cassandra.Keyspace.static(nodes = Set("localhost"))
val cassandraBuilder = Store.Builder(
@@ -25,5 +27,13 @@
cassandra.AggregatesBuilder(keyspaceBuilder)
)
+val loggers = List(
+ LoggerFactory(
+ level = Some(Level.INFO),
+ handlers = List(ConsoleHandler())
+ )
+)
+
CollectorServiceBuilder(Scribe.Interface(categories = Set("zipkin")))
.writeTo(cassandraBuilder)
+ .copy(serverBuilder = ZipkinServerBuilder(9410, 9990).loggers(loggers))
HAProxyで負荷分散
お好みでどうぞ
keepalived で VIP を持たせる
こちらもお好みで